
CSAPP LAB-5 手写动态存储分配器
我也大概察觉到我们课程的实验是挑着 CSAPP 中原版实验去做的,并进行了简化,所以和网上的实验顺序不太一样,但内容是大致相同的。
- 站内文章CSAPP LAB-1 位操作
- 站内文章CSAPP LAB-2 二进制炸弹实验
- 站内文章CSAPP LAB-3 缓冲区溢出炸弹
- 站内文章CSAPP LAB-4 代码优化
- CSAPP LAB-5 手写动态存储分配器(本文)
这次的实验建议先看课本的第九章的 9.9 部分(《CSAPP》第三版),理解其中的内容后进行实现。而且大部分代码课本上都有。不管你现在《CSAPP》学到哪一个部分,都可以直接看 9.9 章,不用担心没有铺垫内容。
本文将介绍一个动态存储分配器的简单实现:隐式空闲链表 + 立即边界标记合并方式 + 首次匹配/下次匹配算法。更高级的实现可以看文末参考文章。
这是我 CSAPP 课程的最后一个实验了,每次专挑👩助教验收,温柔贴心给分高😍!
实验介绍和要求
本实验需要用 c 语言实现一个动态的存储分配器,也就是你自己版本的 malloc,free,realloc 函数。
解压文件:
1 | tar xvf malloclab-handout.tar |
我们需要修改的唯一文件是 mm.c,包含如下几个需要实现的函数:
1 | /* |
记住哦,本次实验的任务要求之一是指针是 8 字节对齐的。
我们可以调用实验提供给我们的函数,这些函数定义在 memory.c 中:
void *mem_sbrk(int incr): Expands the heap by incr bytes, where incr is a positive non-zero integer and returns a generic pointer to the first byte of the newly allocated heap area.void *mem_heap_lo(void): Returns a generic pointer to the first byte in the heap.void *mem_heap_hi(void): Returns a generic pointer to the last byte in the heap.size_t mem_heapsize(void): Returns the current size of the heap in bytes.size_t mem_pagesize(void): Returns the system’s page size in bytes (4K onLinux systems).
在这篇文章的实现方式中,只需要使用 void *mem_sbrk(int incr),与标准实现不同的是,这个函数拒绝收缩堆的请求,也就是不能输入负数。mem_sbrk 的作用可以结合课本 9.9 章进行理解。
验证我们的动态的存储分配器:
mdriver.c:负责测试mm.c的正确性,空间利用率和吞吐量- 执行
make指令生成mdriver可执行文件 mdriver的使用:-f <tracefile>:-f后添加一些 trace file 来测试我们实现的函数-V: 打印出诊断信息。- 例如:
./mdriver -V -f short1-bal.rep
一些编程规则:
- 不能改变
mm.c中函数接口 - 不能直接调用任何内存管理的库函数和系统函数
malloc,calloc,free,realloc,sbrk,brk - 不能定义任何全局或者静态复合数据结构如
arrays,structs,trees,允许使用integers,floats以及pointers等简单数据类型 - 返回的指针需要 8 字节对齐
关键概念
我把课本涉及到的关键概念模型简要介绍一下。
本文介绍的是隐式空闲链表 + 立即边界标记合并方式 + 首次匹配/下次匹配算法。
更多详细内容理解就看下一节的代码注释咯!
隐式空闲链表的恒定形式
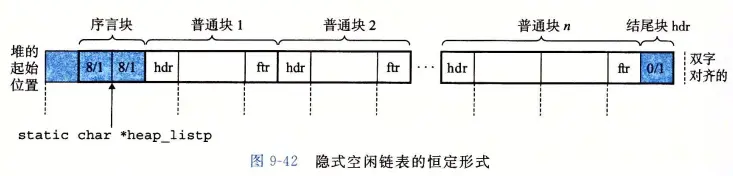
一个正方形表示 4 字节(一个字),虚线表示双字对齐标志。正方形中的头部尾部标记为 size/is_alloc。
标记边界合并
Knuth 提出了边界标记技术,允许在常数时间内进行对前面的块的合并。
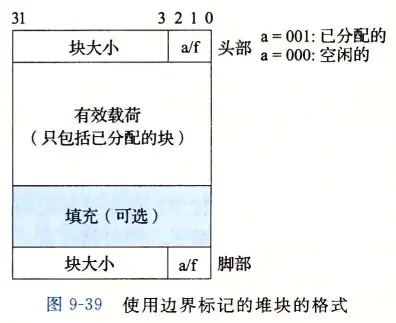
这种思想,是在每个块的结尾处添加一个脚部(footer,边界标记),其中脚部就是头部的一个副本。如果每个块包括这样一个脚部,那么分配器就可以通过检查它的脚部,判断前面一个块的起始位置和状态,这个脚部总是在距当前块开始位置一个字的距离。
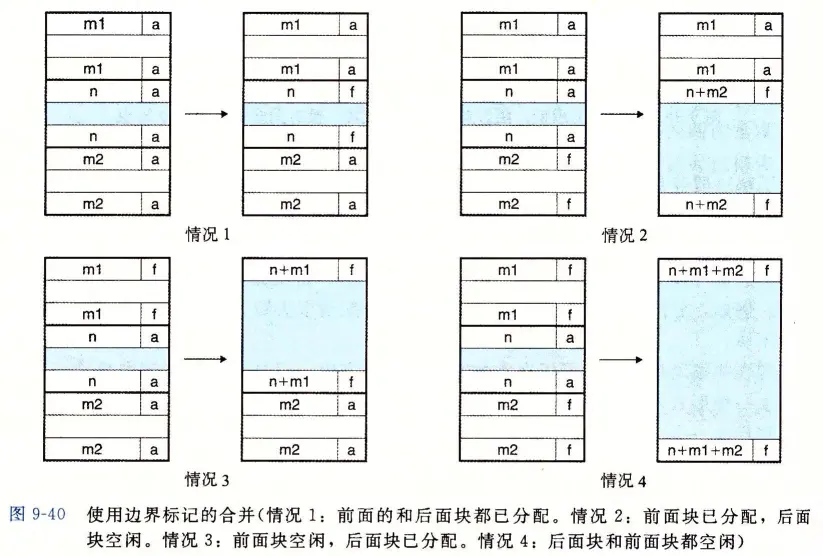
考虑当分配器释放当前块时所有可能存在的情况:
- 前面的块和后面的块都是已分配的。
- 前面的块是已分配的,后面的块是空闲的。
- 前面的块是空闲的,而后面的块是已分配的。
- 前面的和后面的块都是空闲的。
匹配算法
匹配算法:
- 首次匹配(First Fit)。从头开始搜索空闲链表,选择第一个合适的空闲块。
- 优点:趋向于将大的空闲块保留在链表的后面。
- 缺点:它趋向于在靠近链表起始处留下小空闲块的「碎片」,增大了对较大块的搜索时间。
- 下一次适配(Next Fit)。和首次适配很相似,只不过不是从链表的起始处开始每次搜索,而是从上一次查询结束的地方开始。由 Donald Knuth 提出。基于思想:如果上一次在某个空闲块里发现了一个匹配,那么很可能下一次我们也能在这个剩余块中发现匹配。
- 优点:比首次适配运行起来明显快一些。
- 缺点:内存利用率比首次匹配低。
- 最佳适配(Best Fit)。最佳适配检查每个空闲块,选择适合所需请求大小的最小空闲块。
- 优点:内存利用率较高。
- 缺点:在简单空闲链表组织结构中(比如上面提到的隐式空闲链表),需要对堆进行彻底搜索。
mm.c 文件
1 | /* |
后记
这个实验,手打代码,bug 真多。真不能相信肉眼对照,只能信 CV 大法。
限于教学安排和本人时间,CSAPP LABS 就更新到这里。其实这些实验要基本完成也并不困难,在操作的同时可以学到许多 C 语言的知识,积累编程经验,对后续理解计算机都有帮助。
希望大家在知识的海洋里、在存储器山中收获满满!🥳🥳🥳
本文参考

 微信
微信 支付宝
支付宝



