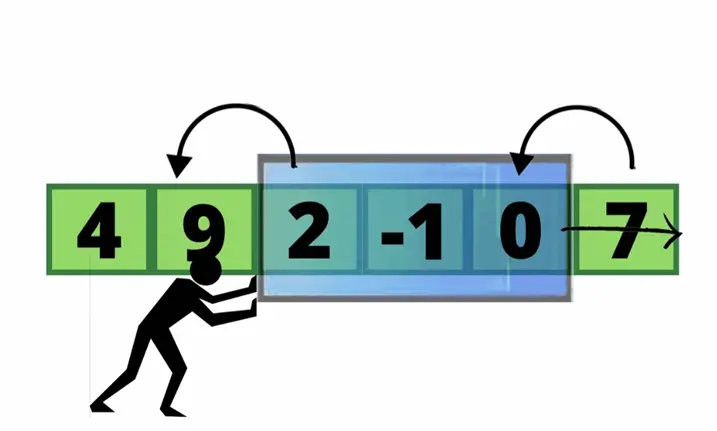
最近最少使用(Least Recently Used,LRU),是一种常用的页面置换算法,选择最近最久未使用的页面予以淘汰。该算法赋予每个页面一个访问字段,用来记录一个页面自上次被访问以来所经历的时间 t,当须淘汰一个页面时,选择现有页面中其 t 值最大的,即最近最少使用的页面予以淘汰。
Java 中可以使用 LinkedHashMap 轻松实现一个 LRU 缓存。
页面置换算法
在进程运行过程中,若其所要访问的页面不在内存而需把它们调入内存,但内存已无空闲空间时,为了保证该进程能正常运行,系统必须从内存中调出一页程序或数据送磁盘的对换区中。但应将哪个页面调出,须根据一定的算法来确定。通常,把选择换出页面的算法称为页面置换算法(Page-Replacement Algorithms)。
- 最佳置换算法(OPT)
- 先进先出置换算法(FIFO)
- 最少使用置换算法(LFU)
- 最近最少使用置换算法(LRU)
附:高速缓冲器替换算法有:随机算法、FIFO、LFU、LRU
本文题目难度标识:🟩简单,🟨中等,🟥困难。
手写 LRU 缓存
请你设计并实现一个满足 LRU(最近最少使用)缓存 约束的数据结构。
实现 LRUCache 类:
LRUCache(int capacity) 以 正整数 作为容量 capacity 初始化 LRU 缓存int get(int key) 如果关键字 key 存在于缓存中,则返回关键字的值,否则返回 -1 。void put(int key, int value)
- 如果关键字 key 已经存在,则变更其数据值 value
- 如果不存在,则向缓存中插入该组 key-value 。如果插入操作导致关键字数量超过 capacity ,则应该 逐出 最久未使用的关键字。
函数 get 和 put 必须以 O(1) 的平均时间复杂度运行。
Java 实现要点:
HashMap + 双向链表。HashMap 用于快速定位双向链表中的结点;双向链表用于区分缓存 key 的访问顺序。- 双向链表必须自己手动建立并维护各种结点操作
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
| public class LRUCache {
class DLinkedNode {
int key;
int value;
DLinkedNode prev;
DLinkedNode next;
public DLinkedNode() {}
public DLinkedNode(int _key, int _value) {key = _key; value = _value;}
}
private Map<Integer, DLinkedNode> cache = new HashMap<Integer, DLinkedNode>();
private int size;
private int capacity;
private DLinkedNode head, tail;
public LRUCache(int capacity) {
this.size = 0;
this.capacity = capacity;
head = new DLinkedNode();
tail = new DLinkedNode();
head.next = tail;
tail.prev = head;
}
public int get(int key) {
DLinkedNode node = cache.get(key);
if (node == null) {
return -1;
}
moveToHead(node);
return node.value;
}
public void put(int key, int value) {
DLinkedNode node = cache.get(key);
if (node == null) {
DLinkedNode newNode = new DLinkedNode(key, value);
cache.put(key, newNode);
addToHead(newNode);
++size;
if (size > capacity) {
DLinkedNode tail = removeTail();
cache.remove(tail.key);
--size;
}
}
else {
node.value = value;
moveToHead(node);
}
}
private void addToHead(DLinkedNode node) {
node.prev = head;
node.next = head.next;
head.next.prev = node;
head.next = node;
}
private void removeNode(DLinkedNode node) {
node.prev.next = node.next;
node.next.prev = node.prev;
}
private void moveToHead(DLinkedNode node) {
removeNode(node);
addToHead(node);
}
private DLinkedNode removeTail() {
DLinkedNode res = tail.prev;
removeNode(res);
return res;
}
}
|
Java 中的 LinkedHashMap

LinkedHashMap 是 Java 提供的一个集合类,它继承了 HashMap 的所有属性和方法,并且在 HashMap 的基础重写了 afterNodeRemoval、afterNodeInsertion、afterNodeAccess 方法。使之拥有顺序插入和访问有序的特性。
LinkedHashMap 特性:
- 支持遍历时会按照插入顺序有序进行迭代。(与
HashMap 的最大区别)
- 支持按照元素访问顺序排序,适用于封装 LRU 缓存工具。
- 因为内部使用双向链表维护各个节点,所以遍历时的效率和元素个数成正比,相较于和容量成正比的
HashMap 来说,迭代效率会高很多。由于双向链表的存在,其插入性能可能会比 HashMap 略低。
LinkedHashMap 逻辑结构如下图所示,它是在 HashMap 基础上在各个节点之间维护一条双向链表,使得原本散列在不同 bucket 上的节点、链表、红黑树有序关联起来。
LinkedHashMap 提供了多个构造方法,包括默认构造方法和带有访问顺序选项的构造方法。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| public LinkedHashMap() {
super();
accessOrder = false;
}
public LinkedHashMap(int initialCapacity) {
super(initialCapacity);
accessOrder = false;
}
public LinkedHashMap(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor);
accessOrder = false;
}
public LinkedHashMap(
int initialCapacity, // 容量大小
float loadFactor, // 负载因子
boolean accessOrder
) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
|
通过指定 accessOrder 参数为 true,可以让 LinkedHashMap 以访问顺序排序(即将最近未访问的元素排在链表首部、最近访问的元素移动到链表尾部),而不是插入顺序。利用这一点,我们可以稍微对其改造,就能得到一个 LRU 缓存。
面试提示
如果面试时考察实现 LRU 的题目,直接使用语言内置特性的做法一般不会符合面试官的要求。但我们还是需要了解如何使用 LinkedHashMap 实现 LRU。
具体实现思路如下:
- 继承
LinkedHashMap;
- 构造方法中指定
accessOrder 为 true ,这样在访问元素时就会把该元素移动到链表尾部,链表首元素就是最近最少被访问的元素;
- 重写
removeEldestEntry 方法,该方法会返回一个 boolean 值,告知 LinkedHashMap 是否需要移除链表首元素(缓存容量有限)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| class LRUCache extends LinkedHashMap<Integer, Integer>{
private int capacity;
public LRUCache(int capacity) {
super(capacity, 0.75F, true);
this.capacity = capacity;
}
public int get(int key) {
return super.getOrDefault(key, -1);
}
public void put(int key, int value) {
super.put(key, value);
}
@Override
protected boolean removeEldestEntry(Map.Entry<Integer, Integer> eldest) {
return size() > capacity;
}
}
|
本文参考
 微信
微信 支付宝
支付宝